
I've spent the last few years commercialising autonomous robots, first at Swiss scaleup ANYbotics and now working on go-to-market (GTM) with several companies across physical AI. Spend enough time around the field and a pattern starts to show up: people are working toward the same goal in two very different ways.
Much of the industry is focused on data-driven approaches, following recent advances in machine learning. A smaller group is focused on getting the architecture right first, informed by real-world deployment and applied research.
Neither approach is obviously right or wrong, and there are strong teams and real capital behind both. But they start from different assumptions, and those assumptions lead to very different companies, which has a knock on effect on commercialisation.
The data-first approach to robotics
The data-first approach follows the scaling playbook that helped crack language and vision in AI. Gather massive amounts of data, train larger and larger models, and let scaling laws do the rest. It is the most popular approach in physical AI today, based on the success of large language models, and the people pursuing it tend to come from language and computer vision backgrounds. Carrying that bet into robotics is reasonable.
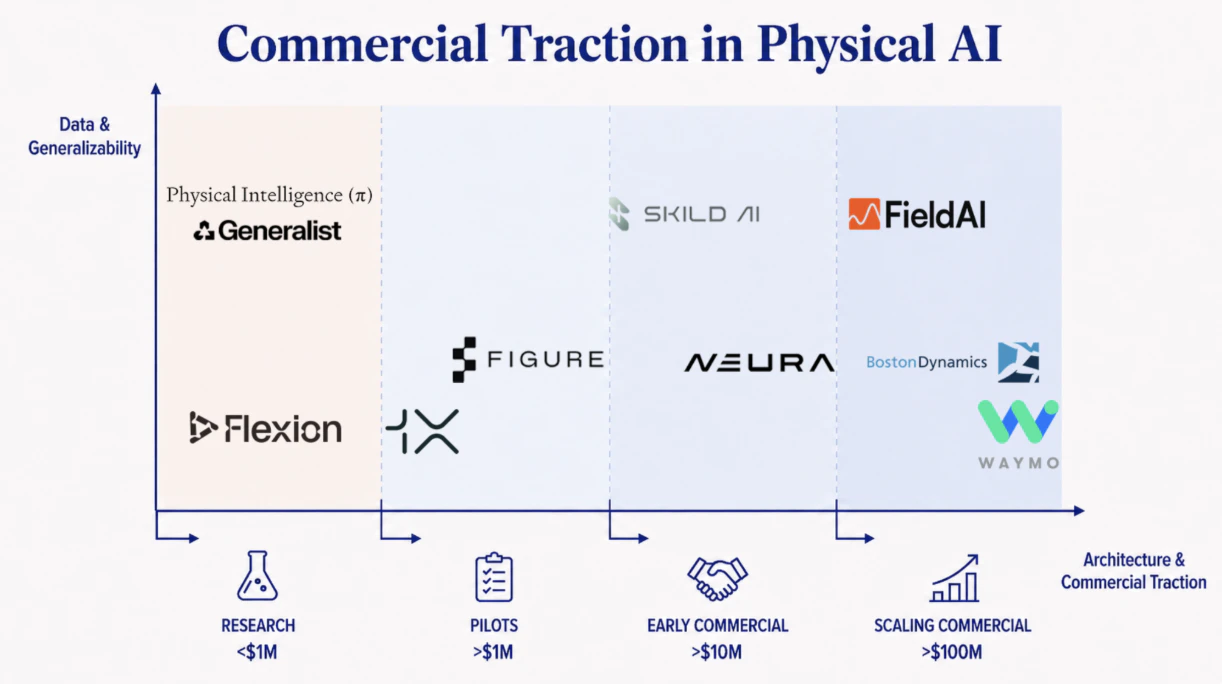
The bet is playing out across well-funded teams on both sides of the Atlantic, among them Physical Intelligence and Generalist in the US, Norway-founded 1X, and Zurich-based Flexion in Europe. Their methods for gathering data vary widely, from video world models and wearable collection devices to large-scale simulation and teleoperation.
Most of the effort here goes into local skills, things like tabletop manipulation or locomotion. The standard method is to pre-train a model on the limited data that exists, then fine-tune it for the specific skill you want. Both steps depend on structured data, and these skills are contained and easy to measure, which makes them a natural fit for benchmarks, demos and academic papers.
The complication is that physical data doesn’t exist at the scale text and images do, and the safety and reliability requirements are greater when you leave the screen. There’s no backspace when you are exerting force in the physical world, so the work has to be constrained.
A model can only be trusted to operate in environments close to the ones it saw in training, what researchers call “in distribution”, so this approach starts in the controlled conditions of the lab and leaves the complexity of the real world for later.
The bet here is that capabilities widen over time, skills get more general and you build wrappers to catch edge cases as they appear, gradually expanding what is considered “in distribution”.
It also counts on future research breakthroughs that are expected to make real-world deployment possible. For now, the hallucinations and black-box reasoning of end-to-end models keep them from operating in complex, safety-critical settings.
The architecture-first approach
The architecture-first approach starts from a different set of assumptions, shaped by the applied research of field robotics and real-world deployment. This method embraces the complexity of the real world from the start, and rather than control the world to suit the model, people are building the model architecture to suit the world as it is.
The teams building this way are fewer, and they tend to come from a field robotics background rather than from language and vision. FieldAI, started by veterans of NASA's Jet Propulsion Laboratory, Google DeepMind and the DARPA robotics challenges, combines Bayesian methods with modern machine learning in its Field Foundation Models, which have been deployed on hundreds of sites across Europe, Asia and North America.
Waymo has made the same architectural bet in autonomous driving. It has researched pure end-to-end models like EMMA, but its deployed Waymo Foundation Model keeps a structured design with interpretable parts and a Bayesian treatment of uncertainty, so its decisions can be checked and verified across millions of driverless miles on public roads.
The central premise is that the physical world calls for a fundamentally different approach than the digital one, and that more data alone will not get you there. Large language models train on trillions of tokens and still hallucinate. Unlike a chatbot, a robot that hallucinates can do real physical harm.
Bringing AI to the physical world is a much harder architectural problem, one that demands the deepest research and mathematical rigour. The system needs to be grounded in physics, quantify its own uncertainty and act on that uncertainty, gathering more information when it needs to and pulling back when the risk is too high. Picture a robot on a worksite when dust kicks up and obscures the view ahead. A system that understands uncertainty slows down and waits for the air to clear before moving forward, the way a careful person would.
The result is a data-efficient and resilient system that understands how the world works and knows what it doesn’t know. It can adapt to dynamic, unstructured conditions it never encountered in training. And because it assumes nothing about a site, it can be dropped somewhere new, with no prior information or supporting infrastructure, and start working the way a new hire would on their first day.
The approach gives customers a level of operational intelligence which sees robots complete long tasks from start to finish, sequence many actions in order and coordinate multiple robots working together. The individual skills still matter, but they are designed around the constraints and imperfections of real world operations from day one rather than adapted later.
Why this matters commercially for robotics companies
My instinct is that operational data compounds in ways synthetic benchmarks and controlled demos don't, and that the organisational know-how you build getting robots to run where they weren't designed to is genuinely hard to replicate from a lab.
An architecture-first system that can deal with uncertainty and adapt to surprises can be put to work now, in real conditions, which is why the teams building this way tend to have more commercial traction.
It also meets customers’ need for operational intelligence that adds value to their existing workflows. And every deployment generates operational data, one of the most scarce and valuable resources in physical AI.
It’s ironic that the approach that needs the least data to get started ends up with the largest amount of high-quality data, the kind with the diversity of conditions and edge cases that only surface in the field. What looks like a head start in architecture is really a head start in deployments and a self-reinforcing data flywheel.
Physical AI is often described as a race. It’s still an open question who the ultimate winners will be, and I won't pretend to know how it resolves. But I know which way the evidence on the ground is pointing.



